
I forgot how depressing working with ML for this problem space is. I fiddled with pandas for a while starting to sketch out different permutations of indicators and running some tests to see if I could get a baseline. It’s always supremely disheartening when you don’t see results out of the gate 😛 but that’s expected. First runs are a bit worse than coin flips out of sample.
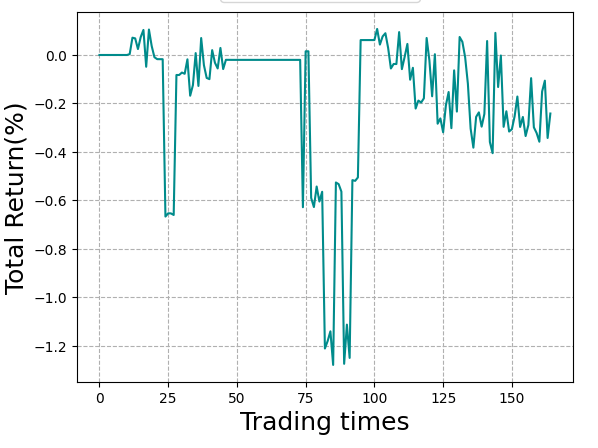
If I exclude some indicators, the performance degrades, so I can see we’re supplying some usable information.
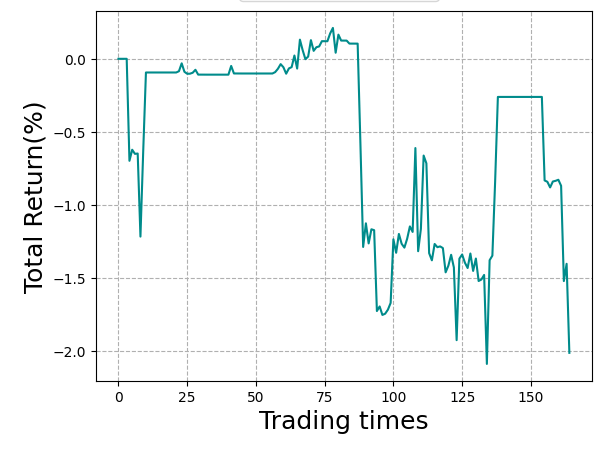
Just have to keep iterating/exploring until things start to click!
With some additional epochs run, you can start to see some semblance of learning and profitable decision making. Although the agent takes a bunch of drawdown, the trend starts to look a bit better. It’s able to take some nice winning positions, but usually gives it back and a little more.
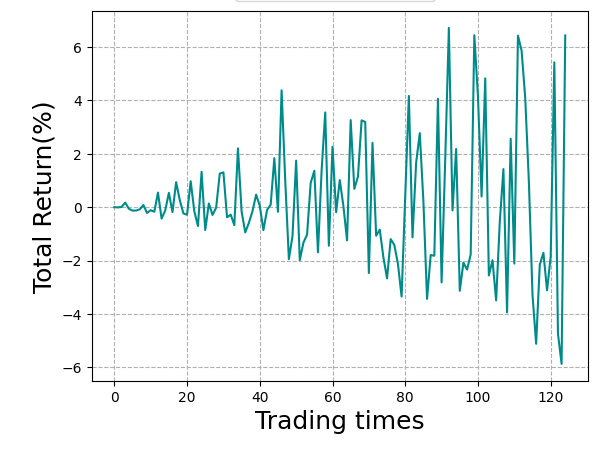
Once the sharpe ratio is hitting 2+ we know we’re getting somewhere, but this is actually a decent start given how bare-bones the feature engineering is. I found a bunch of research for automatic feature discovery as well.

I’ll run one more train with three times the epochs and we’ll see where that lands. At this point I’ve got a pipeline so I can produce the datasets and run the training on a reasonably fast loop. I’m really clueless still about ML workflows – this is definitely not my area of expertise! So I expect a lot of trial and error, and generally wandering around in the dark.
With 150 epochs, my rig sounds like a jet. GPU utilization is pretty low – a lot of the work is very CPU bound so I would get a lot more bang from the GPU if I tossed some cash at the CPU. Maybe once we get some payouts from the prop challenges, I can re-invest a bit.
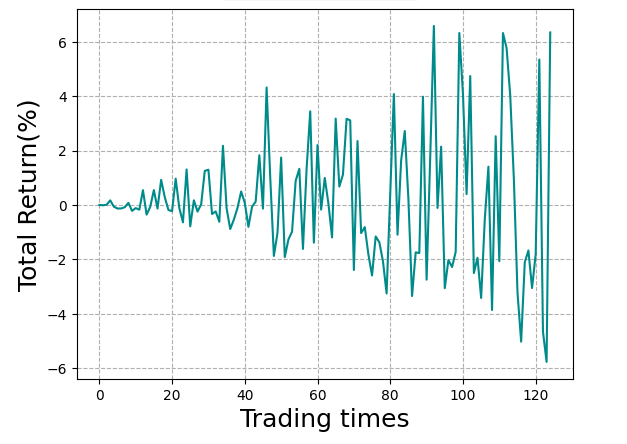
After a boatload of episodes, I can see now we’re not really getting anywhere. The agent can lose money very well, but it’s not so great at making it yet. The final run is a little worse than our previous best.

This is about the limit of what we’re gonna get out of the sample today.






Leave a comment